| One of the most useful methods for modelling surfaces is with a triangular irregular network, or TIN. One aspect of TIN that makes it preferable to a raster grid is that you can put the points anywhere that you want. This means that you can make the points more dense where there is more detail, and more sparse where there is little detail. The surface at the right is actually composed of these irregular triangles. | 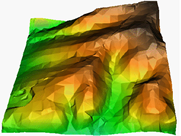 |
| But not all TINs are created equal. The best TIN is the one that maximizes the angles of the triangles; that is, it produces 'fat' triangles rather than 'skinny' triangles. This is because the further away a node of a triangle is from the rest of the triangle (which happens with skinny triangles), the less likely that the point is the same as the rest of the triangle. The First Law of Geography is: "Everything is related to everything else, but near things are more related than distant things." | |
| The way to make these fat triangles is through fulfilling the Delaunay criterion. This criterion states that no point of a triangle can be inside the circumcircle of another triangle. For example, consider the four points to the right. |  |
| Their circumcircles appear as shown. |  |
| Now if you were to make triangles from these points, note that none of the points enters into the circumcircle of the other triangle. They may be on the border of the circumcircle, but they do not enter it. |  |
| To make a TIN with these “fat” triangles, start by making Voronoi polygons. These are polygons around each point in your space. The borders represent the boundary of the space that is closest to each point. Observe the points to which the arrows point as an example. All space within the two polygons that surround these two points is closer to their point than to the points on the other side of the border. |  |
| When you have the Voronoi polygons, connect the points that have adjacent borders. This creates the TIN with fat triangles. | 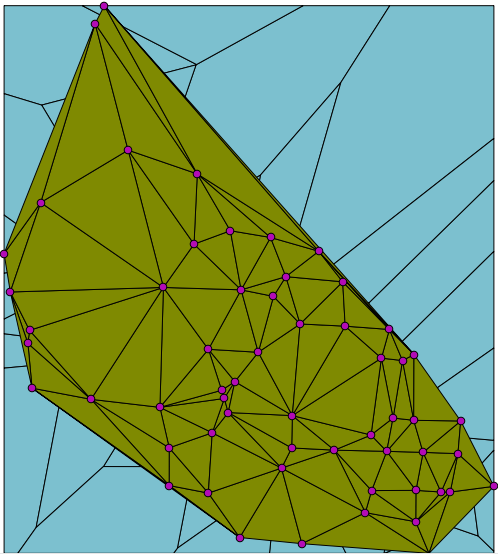 |
I said that TIN was useful, but Voronoi polygons are useful in themselves. For example, imagine that you own a group of grocery stores in a city and that you want to advertise to the community. You could calculate the Voronoi polygons around your stores and direct your customers to the store within each polygon. You would get more customers, and the customers would not know that they are within your Voronoi polygon.
Okay, so most of us will not own a group of grocery stores, how about something more useful? One of the first applications of Voronoi polygons was by John Snow in 1854 during the Broad Street cholera outbreak. Snow created what we now call Voroni polygons around water pumps and demonstrated that most cholera deaths occurred within the area of one water pump. That was just the first of many uses of Voronoi polygons.

 First, look at the Renters layer. This layer shows us that many people in the West End (the red part in top left), a densely packed area of 100,000 people in 100 square blocks, rent their dwelling units.
First, look at the Renters layer. This layer shows us that many people in the West End (the red part in top left), a densely packed area of 100,000 people in 100 square blocks, rent their dwelling units.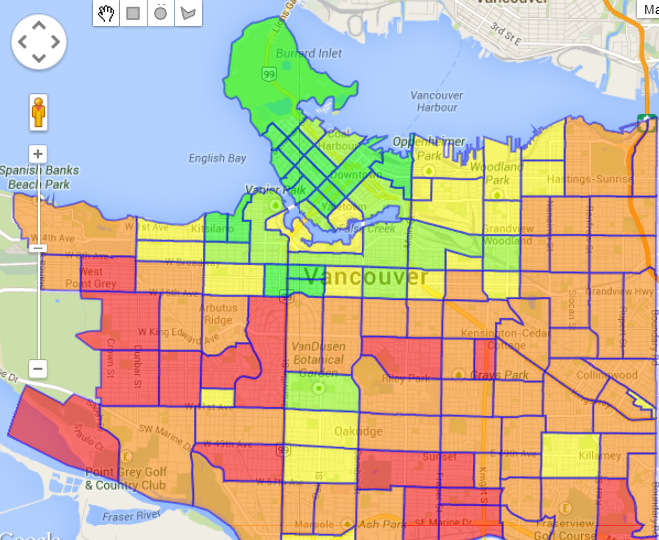
 Finally, look at the Family – average size layer. This layer is similar to the Population – 14 years and under layer; the south part of Vancouver has large families, while in the West End, families are not large.
Finally, look at the Family – average size layer. This layer is similar to the Population – 14 years and under layer; the south part of Vancouver has large families, while in the West End, families are not large.
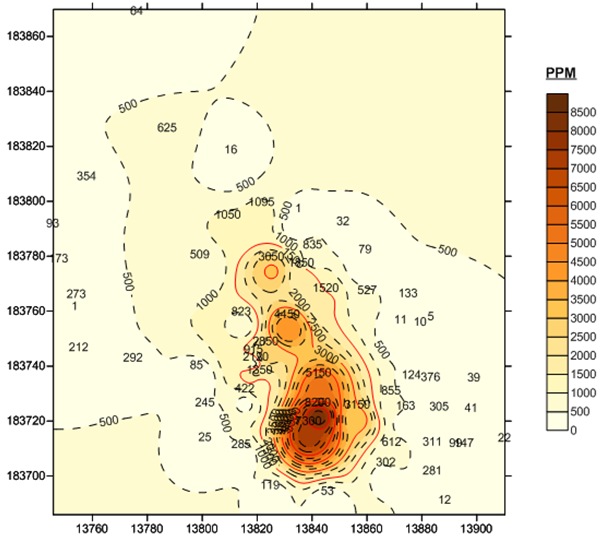
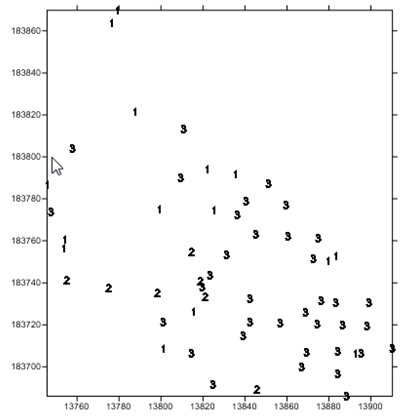 Consider, for example, that there has been an oil spill in a certain area, and that engineers have taken samples of the area, measuring for hydrocarbons. They give the samples to you and ask you to provide a picture of the entire area.
Consider, for example, that there has been an oil spill in a certain area, and that engineers have taken samples of the area, measuring for hydrocarbons. They give the samples to you and ask you to provide a picture of the entire area. 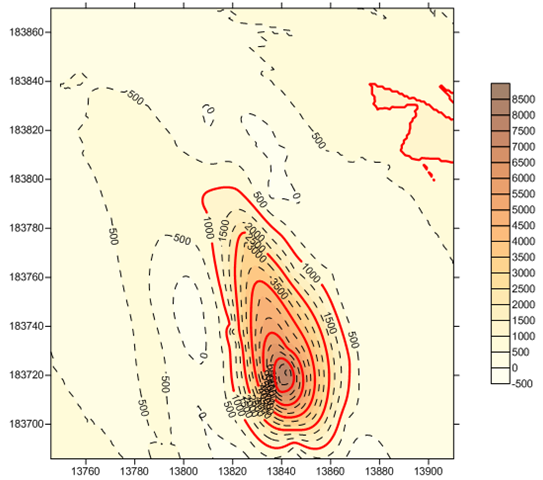
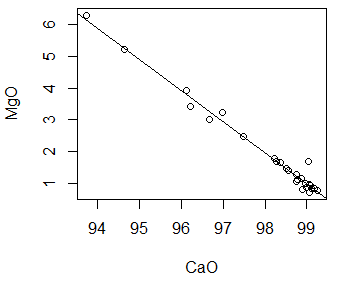
 It is a scatterplot where each point represents the value of magnesium for a given value of calcium in limestone.
It is a scatterplot where each point represents the value of magnesium for a given value of calcium in limestone.